I am writing these series of posts to challenge myself to enhance my skill in communciating machine learning and statistical concepts to others in an intuitive way
Introduction
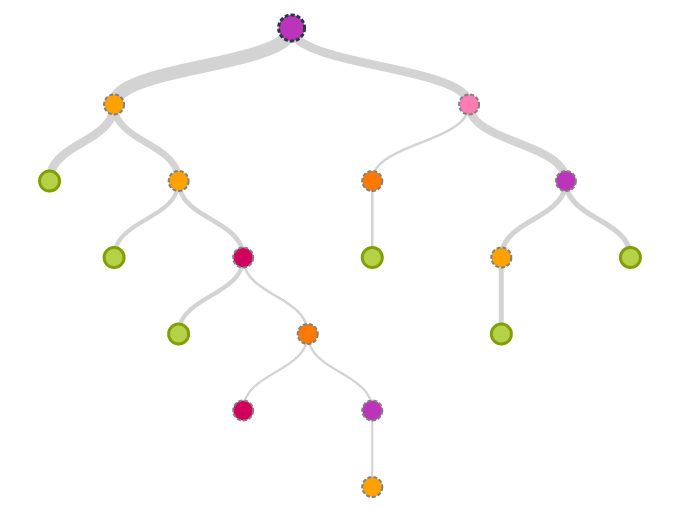
Decision trees are a class of machine learning algorithms that decide the output class of a datapoint based on a series of binary decisions using the variables in the dataset.
This split is generally called binary recrusive split and happens at each step of the tree. A single parent node will be split into 2 child nodes based on a particular variable.
At the end of it, we obtain the final child nodes which are called leaves. Now the number of leaves that can be created depends on how we long we want the tree to grow.
For example, if there are a 100 students and each of them have their resident status listed as either resident or non-resident. Now at the first split of the decision tree, the entire 100 students will be split into 2 groups, resident or non-resident based on the data.
How does this happen?
Well, in real life scenario we will have more than one variable that describes a particular datapoint like age, sex, occupation e.t.c.
In this case, there are multiple methods that are used to determine the best variable to be used to split the data at a particular step.
Gini index : Gini index gives a measure of total variance across all the classes and the smaller Gini index indicates higher node purity.
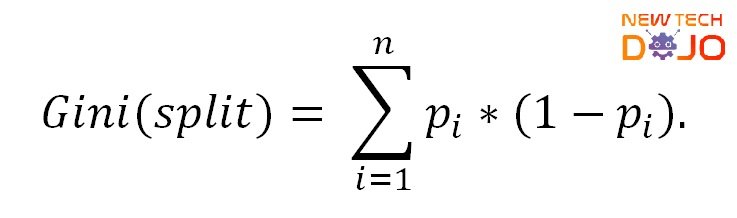
Entropy : This metric is used to calculate the purity of child nodes that are created after splitting the parent node. Higher the purity of the child nodes, lesser is the entropy.
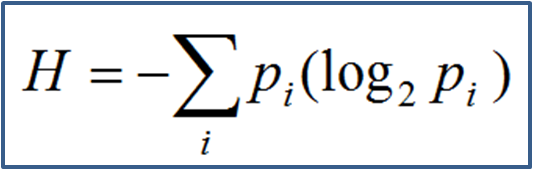
Chi-square : Chi-square value is calculated for each variable for the available data at that step of the decision tree. Higher the chi-square value, higher is the important of the variable.
Hyperparameter tuning:
If the tree grows too large, there is a chance for overfitting. It means that the tree will have high variance and will give high error rates for any new test data. To avoid, we generally perform cross validation on a particular metric like rmse to select the number of leaves that are reasonable to avoid overfitting. We can have various metrics to find the optimal parameters such as accuracy and misclassification error rate. We can tune multiple other parameters of a tree like maximum number of datapoints in each child node, minimum datapoints required to split a parent node into children nodes e.t.c
Generally, there are 3 types of search techniques that we use for hyper parameter tuning.
- Grid search : We specify a list of parameters that we think would be reasonable for the data we have and the algorithm searches for all the combinations.
- Random search : The algorithm picks the combinations randomly and decides on the final combinations that will reduce the cost
- Bayesian parameter optimization : In this method, the knowledge from the previous combination will be carried to the search of the next combination. In other words, the second combination will be conditional on the output of the first combination and continues accordingly.
All these algorithms run on different folds of cross validation data to decide on the best parameters for the trees.
Pruning:
There is one more method to avoid overfitting of the tree called Pruning. In this method, we let the tree grow to its maximum possible size and at the end we prune the tree based on k-fold cross validation technique.
Pruning method randomly removes branches from the trees and calculates the error rate or misclassification rate of the tree. For every subsequent step,if the error rate increases on removing a particular branch, the branch will be replaced back to the tree.
If the cross validation error rate decreases, the branch will be permanently removed from the tree and the nodes would become the final nodes at that part of the tree.
This method is more technically called “Cost-complexity pruning”.
That’s all folks. See you later in the next article.