I am writing these series of posts to challenge myself to enhance my skill in communciating machine learning and statistical concepts to others in an intuitive way
Boosting models are some of the most famous machine learning algorithms. There fame comes from the fact that they learn from their mistakes during the process sequentially.
This helps those models to actually build on top of the mistakes and give faster and better results.
In this post, we will be looking into the following aspects:
1. Introduction to different kinds of boosting models and how they work
2. What are the reasons for the fame of XGBoost
Boosting:
We all know boosting models belong to the family of ensemble methods which tend to produce strong learners by combining multiple weak learners. Following is the picture that briefly explains the different kinds of ensembling.
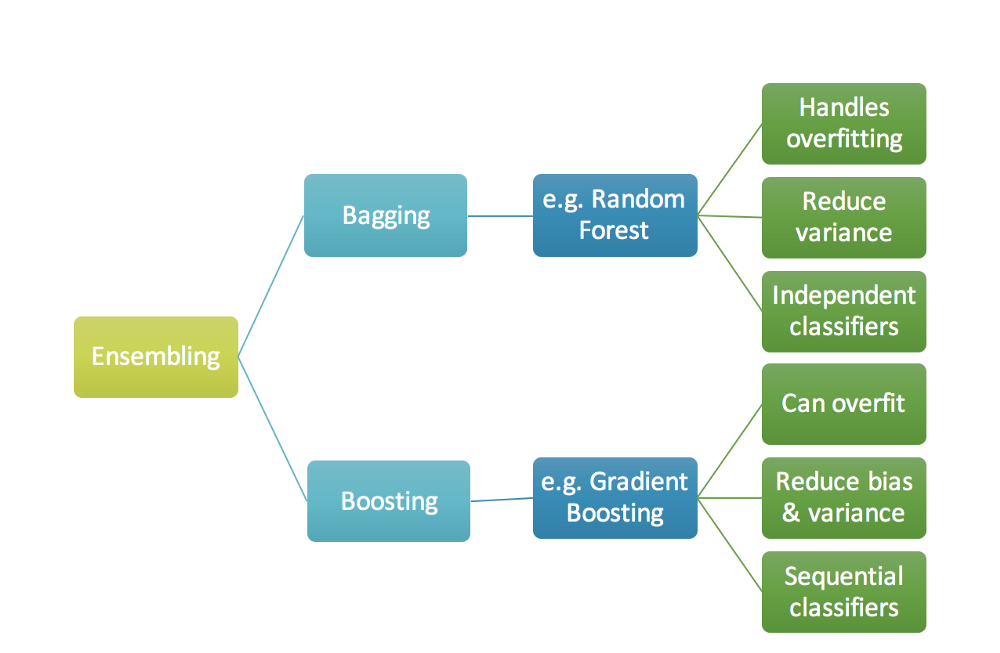
Boosting is mainly different from bagging for one and only reason - sequential learning. In boosting, the model learns from its mistakes sequentially whereas in bagging the ensembling happens at the last step. Here, we take the residuals of the first model and build model on top of the residuals sequentially to identify the patterns that are not identified by the first model.
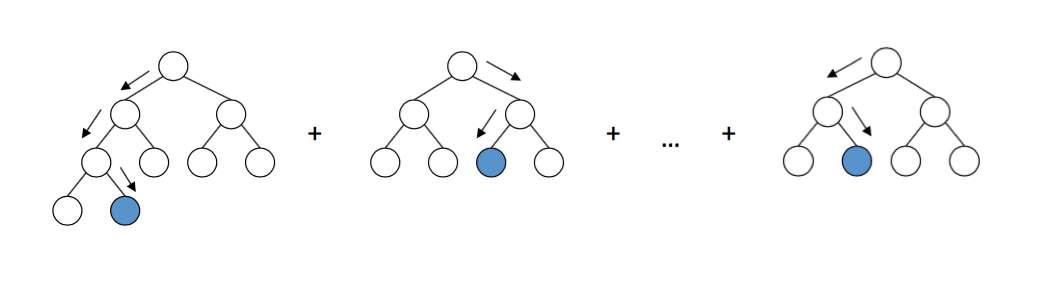
Adaboost:
Adaboost,short for Adaptive boosting, is a boosting model that is sensitive to the errors in the previous models. At each step, the model would be penalized for instances of misclassification and would be forced to make the right decision in the next iteration to reduce the total error.In Adaboost, this is traditionally performed by adding weights to the errors that occur at each step of the model.
You can see below at each step, the decision stump is decided based on the weights assigned to each point. This changes continuously to reduce the final error.
In the final step, all these decisions combined together will give the classification of the dataset.
For detailed mathematical explanation, you can refer here
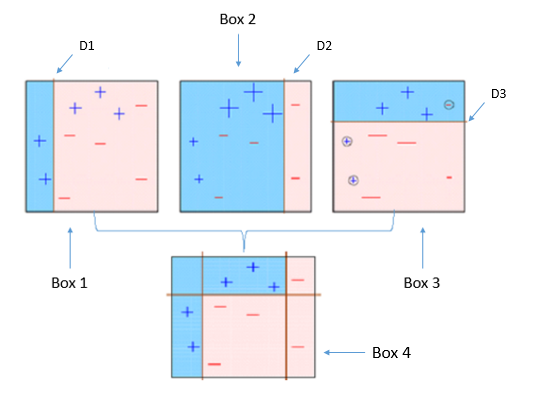
However, there are some limitations to Adaboost model:
1. They are sensitive to noisy and pose the risk of assigning more weight to noise
2. The same problem would be applicable to outliers also
This takes us to our next model.
Gradient Boosting:
In Adaboost, the primary task is to minimize the loss and one of the best ways to do that is to find the global minima of the loss function using a gradient descent model. Gradient boosting trees use gradient descent optimization method to optimize the parameters by fitting a new model at each iteration. This class of algorithms were also described as a stage-wise additive model. This is because one new weak learner is added at a time and existing weak learners in the model are frozen and left unchanged.
Gradient boosting is an additive model. In a general gradient descent application like regression, we optimize the parameters to achieve minimized loss. But in this case, we add one tree at each step and optmize the parameters of the tree that give minimum residual loss at that step. This is generally called gradient descent in functional space. This process is repeated at each step till we arrive at the specified number of trees to be used or by early stopping.
By the end of the final iteration, we would have arrived at a model that had learnt from the mistakes of the previous models sequentially and gives out the best predictions.
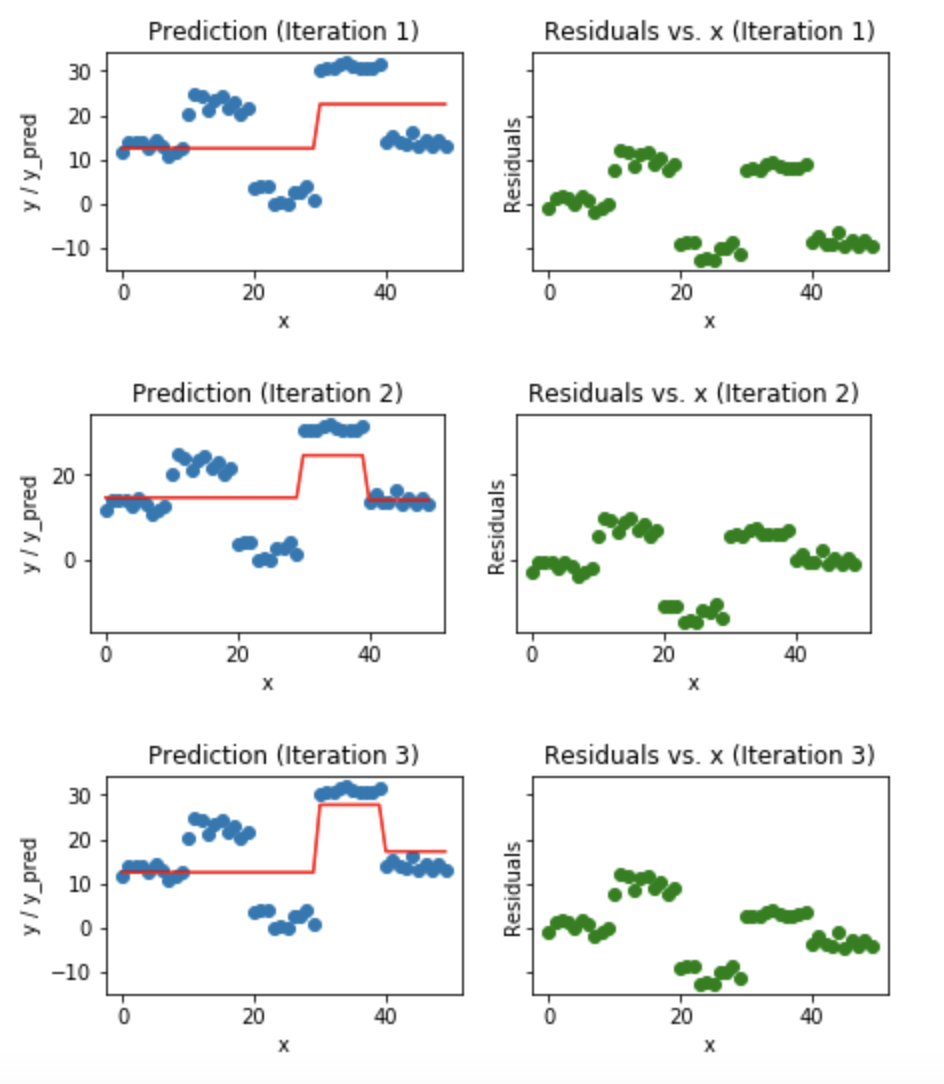
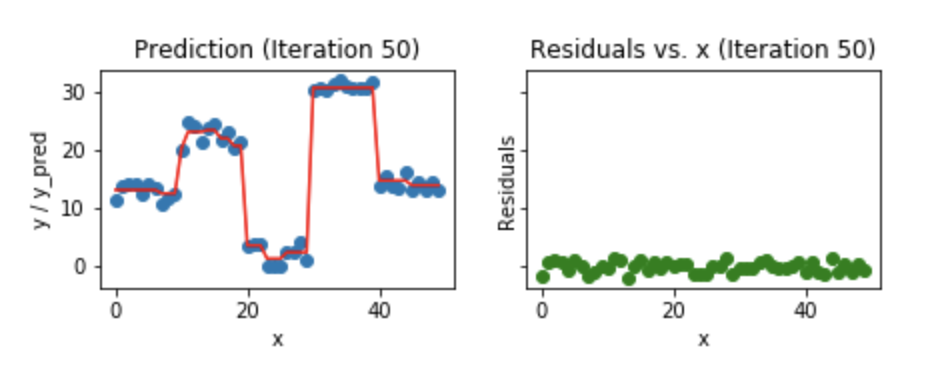
We could should be cautious of overfitting as we increase the number of iterations for a given dataset and this warrants the use of regularization parameters.
Key features:
1. Any differentiable loss function can be optimized using gradient descent method
2. Gradient descent happens in functional space
3. Parameters of the tree are often set through cross validation
4. Early stopping is required to avoid overfitting
XGBoost:

If you are part of the Kaggle eco system, then there is high chance that you would have heard about XGboost algorithm and its potential to deliver results with high speed and performance.
XGboost,short for Extreme gradient boosting, is an algorithm that is designed for increasing speed and performance using Gradient boosting trees. Tianqi chen developed this algorithm while he is doing his Ph.d in University of Washington. XGboost is an implementation of gradient boosting trees which increases the speed and performance of the model by taking advantage of parallelization and distributed computing.
Most important features of XGBoost can be divided into
System features
It enables of the parallelization of tree construction using all cores during training
Distributed computing is made possible using cluster of machines using XGBoost
It employs the concept of cache optimization which makes it more efficient
Algorithmic features
1.Sparse aware: It automatic handling of missign data values
2.Block structure: It supports parallelization of tree structures as mentioned already in the system features
Key points to remember while running an XGBoost model:
1. Avoid overfitting by using early stopping
2. Use cross validation while pruning the trees
3. Use xgb.Dmatrix to create train and test datasets
4. Always perform hyperparameter search(Random search would work well than Grid search)
That’s all folks. See you later in the next article. Happy learning!
References:
[1] https://towardsdatascience.com/boosting-in-machine-learning-and-the-implementation-of-xgboost-in-python-fb5365e9f2a0
[2] https://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/
[3] https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d
[4] https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052
[5] http://blog.kaggle.com/2017/01/23/a-kaggle-master-explains-gradient-boosting/
[6] http://statweb.stanford.edu/~jhf/ftp/trebst.pdf
[7] https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/